
Just starting this page to share what AI tools I have been playing with. Kind of a journal, but might write up separate articles if I end up using any of these in my regular workflow.
—————
20260203
Haven’t been updating this. My bad. But here is a quick update.
Using Cursor for some agentic coding now. Haven’t tried Claude Code or Google, heard good things, but they are generally harder to get access to in China and Hong Kong. So I just use Cursor. Trying hard to keep cost down.
Remember to spend time to setup good AGENTS.md and .cursorrules files to help your agent to help you.
I know it sounds bad or just lazy, but for $0.03-0.06, you can just use the agents to do a proper git push, with a good summary of what has been updated. Sure, there are ways to be stingy and do it all yourself, but this is exactly why old code bases often have messy git history. Devs usually don’t spent time on documentation and won’t spend a few minutes writing git push notes.
Ralph Wiggum seems to be a “hot topic”. https://www.youtube.com/watch?v=5xvP9O4msLM
Guess it is not a bad idea, if you don’t mind burning some credits on wasted loops.
Even at a playing around stage, I can easily use 30 bucks in about 2 hours or so in refactoring an open source project. Was “lucky” to have it working, but can easily have ended up with 30 bucks and 2 hours wasted.
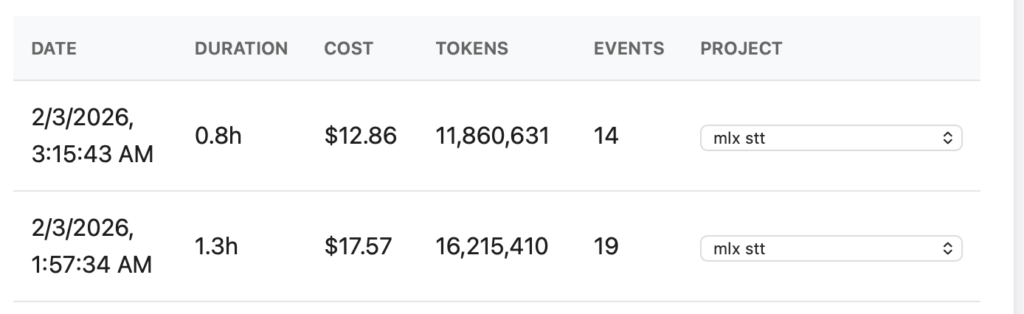
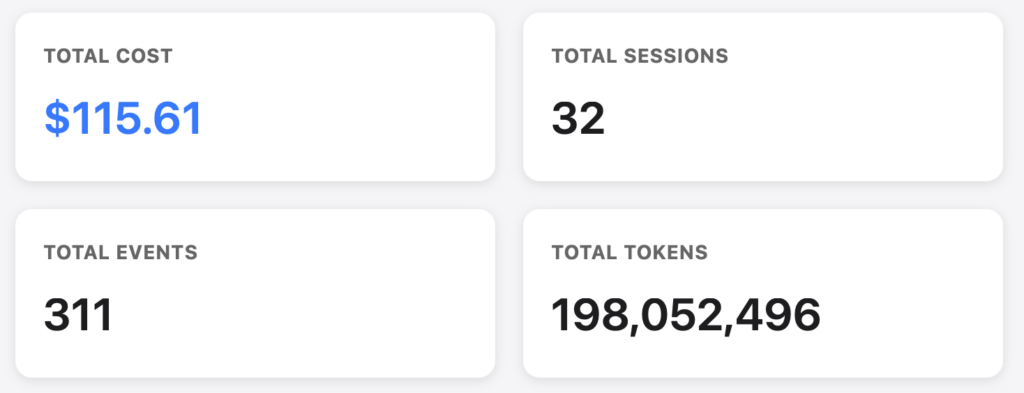
Yes, it is important to track your AI Coding Costs. This is my tracked usage so far. This is a small tool I built for analysing the Cursor
—————
20250728
Try this new repo. Can be fun.
https://jerryliang24.github.io/DnD
https://github.com/jerryliang24/Drag-and-Drop-LLMs
—————
20250718
Played around with RAG a little. Easy with Ollama on a Mac. Need basic Python skills.
https://medium.com/@eplt/local-rag-chatbot-with-ollama-on-mac-4d4b37f977b4
———-
20250612
Useful command to remove all Ollama models and start again.
ollama list | awk 'NR>1 {print $1}' | xargs -I {} ollama rm {}—————
20250226
https://www.cursor.com this is the hot tool for developers, finally got around to try it out.
Been using Codeium and Co-Pilot a bit more for my bash scripting. Saving me a lot of time fiddling with regex patterns which I can never remember the differences between all languages. Just write down your expected input and output examples, they will fill in the code. Can usually get it working after a couple of tweaks.
—————
20250217
AI can easily help with grep/regex patterns. Just give it a few examples of input and expected output and it works out the pattern needed in the coding language you need. Then test it yourself.
Prompt:
can you give me the code to change
input:’https://fastly.picsum.photos/id/609/192/108.jpg“; output:’https://picsum.photos/id/609/1920/1080.jpg“
input:’https://fastly.picsum.photos/id/806/192/108.jpg“; output:’https://fastly.picsum.photos/id/806/192/108.jpg“
in javascript
function modifyImageUrl(url) {
const regex = /https:\/\/fastly\.picsum\.photos\/id\/(\d+)\/192\/108\.jpg/;
const match = url.match(regex);
if (match) {
return `https://picsum.photos/id/${match[1]}/1920/1080.jpg`;
}
return url;
}
// Example usage:
const input1 = 'https://fastly.picsum.photos/id/609/192/108.jpg';
const output1 = modifyImageUrl(input1);
console.log(output1); // Output: 'https://picsum.photos/id/609/1920/1080.jpg'
const input2 = 'https://fastly.picsum.photos/id/806/192/108.jpg';
const output2 = modifyImageUrl(input2);
console.log(output2); // Output: 'https://fastly.picsum.photos/id/806/192/108.jpg'—————
20250119
To process many PDFs, install these.
brew install poppler
brew install ocrmypdf—————
20250117
Play around with the context size for different models. Default ollama context size is 2048. Don’t go wild as you will get odd results.
https://github.com/ollama/ollama/issues/8356#issuecomment-2579221678
$ ollama run llama3.2
>>> /set parameter num_ctx 4096
Set parameter 'num_ctx' to '4096'
>>> /save wizard
Created new model 'wizard'
>>> /bye
$ ollama show wizard
Model
architecture llama
parameters 3.2B
context length 131072
embedding length 3072
quantization Q4_K_M
Parameters
num_ctx 4096
stop "<|start_header_id|>"
stop "<|end_header_id|>"
stop "<|eot_id|>"
License
LLAMA 3.2 COMMUNITY LICENSE AGREEMENT
Llama 3.2 Version Release Date: September 25, 2024
$ ollama run wizard
>>> hello
Hello! How can I assist you today?
>>> /byeBackground reading about Context Window: https://cheatsheet.md/chatgpt-cheatsheet/chatgpt-context-window
—————
20250108
There are many cool models to play around with on Ollama. Try these: Qwen, Granite, Deepseek, Llama, Gemma.
—————
20250104
Been playing around with open source AI models quite a bit in 2024. They are getting much better. One of the key development has been the context length of these models. The “original” ChatGPT that we started with in 2022 (yes, only 2 years ago), was only 4096 tokens. Loosely meaning that only the first 4096 “important” words in your input matters. The newer models can now do 128k tokens. A typical non-fiction book has between 50,000 and 75,000 words. Kind of loosely means the current models can now read the whole book in one shot. That’s a big deal, because as humans, when we read a book, by the end of it, we would have forgotten about the a few chapters back, but the new models can process them all at once.
And it’s not just OpenAI that can do these. Many new models are already way better than the ChatGPT we were amazed by 2 years ago. At least 3 of these models are by Chinese teams, Qwen, Yi and Deepseek. Even with the trade war, etc, etc. Interesting times ahead.
—————
20240807
Using open source LLM can be confusing, so many choices, even for the same model, there are so many variants. Here are a few articles which help to explain what they are:
* Base, Instruct, Chat and Code models
* Parameters or Model size (8B, 14B, 70B and more)
* Quantisation
* Context size (8k, 32k, 128k)
https://thoughtbot.com/blog/understanding-open-source-llms
https://www.reddit.com/r/LocalLLaMA/comments/142q5k5/updated_relative_comparison_of_ggml_quantization/
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
20240807
Leaderboard of which LLM is best for code editing and refactoring.
https://aider.chat/docs/leaderboards/
https://aider.chat/2024/07/25/new-models.html
I am using deepseek-coder for now https://ollama.com/library/deepseek-coder:latest
20240807
Another app to play around with on Mac, to add LLM integration to your system, a quick shortcut key and you can have direct answers from top LLMs online or local on your computer. alter – https://alterhq.com/
20240807
Even Apple Intelligence will be making good use of prompt engineering with ChatGPT. Wider discussion on stochastic vs deterministic computing. They are not explicitly programming instructions for the LLMs, but using natural language to instruct the LLMs to get the result with certain levels of unpredictability. The programming world will take time to adjust as they have mostly been doing imperative programming all along. Stochastic is not just useful for AI, but for quantum computing.
To play around with it, you will need to install macOS 15.1 beta, not 15 beta. You will find the files inside /System/Library/AssetsV2/com_apple_MobileAsset_UAF_FM_GenerativeModels
Source: https://www.reddit.com/r/MacOSBeta/comments/1ehivcp/macos_151_beta_1_apple_intelligence_backend/
20240807
Another useful prompt with GPT-4o to get clean JSON output.
Please generate a JSON response that adheres strictly to the following schema. Do not add or remove any fields, and make sure to follow the exact structure.\n\n${json_scheme}\n\nFill in the placeholders with appropriate values based on the image the user sends. Don't return with backticks, simply return with the json
20240727
Use “–verbose” option with ollama to display the performance of the model.
e.g. ollama run llama3.1:70b-instruct-q4_0 –verbose
total duration: 1m29.230942s
load duration: 40.905541ms
prompt eval count: 26 token(s)
prompt eval duration: 2.024605s
prompt eval rate: 12.84 tokens/s
eval count: 1013 token(s)
eval duration: 1m27.162336s
eval rate: 11.62 tokens/s
Can’t run the 405B model on my Mac Studio M1 Ultra with 64GB RAM.
Will try this soon, to distribute the load to 2 (or more) Macs.
Eco Labs + MLX.
https://x.com/ac_crypto/status/1815969489990869369
https://x.com/awnihannun/status/1815972700097261953
Hard to say that I need the largest model. But the idea of being able run that at home seems cool. The 70B model is the one I use on my laptop. Waiting for codellama to be updated to use 3.1.
20240724
Llama 3.1 is out, available in 8B, 70B, and 405B versions. It’s big. I need to cleanup my Mac Studio to play with the 405B, currently just testing with the 70B version.
https://www.marktechpost.com/2024/07/27/llama-3-1-vs-gpt-4o-vs-claude-3-5-a-comprehensive-comparison-of-leading-ai-models/
To cleanup Ollama a little, use “ollama list” to show the currently installed models and “ollama rm <model name>” to remove a model. New 405B will take up 231GB.

20240723
Getting Copilot setup again. Want to play around with coding with AI again. (Kind of annoying that I don’t get the 30-day free trial as participated in the year-long Technical Preview.)
Try Codeium too.
I am setting it up for Xcode and VSCode. You will need https://github.com/intitni/CopilotForXcode and https://github.com/intitni/CodeiumForXcode
Will need to install nvm and node; use “which node” to check the path of your node installation.
20240517
Been playing with Llama 3 on my Mac. Easy to install with Ollama https://ollama.com. Might try out Gemma and Mistral eventually too. Llama 3 isn’t great for Chinese output. There is another tweaked model. https://huggingface.co/shenzhi-wang/Llama3-70B-Chinese-Chat , will figure out how to use that soon.
20240516
Using Audio Hijack from Rogue Amoeba to transcribe some old voice recording. It’s not bad. Powered by Whisper https://github.com/openai/whisper
Also found a free app, Aiko, that use Whisper to do the same on the Mac. https://apps.apple.com/us/app/aiko/id1672085276
Leave a Comment